理解单链表
发表于更新于
字数总计:3.3k阅读时长:11分钟 四川
解读单链表-C语言实现
链表的概念及结构
概念: 链表是一种常见的数据结构,在计算机科学中被广泛使用。它是由一系列节点组成的集合,每个节点包含实际存储的数据信息(称为元素或数据域)以及一个指向下一个节点的引用(称为链接或指针)。链表不像数组那样在内存中连续存储元素,而是通过节点之间的链接来组织数据。
首先来梳理链表的一些基本概念:
-
节点(Node):链表中的一个元素,通常包含数据域和链接域。数据域用于存放实际的数据值,而链接域则存储指向列表中下一个节点的引用。
-
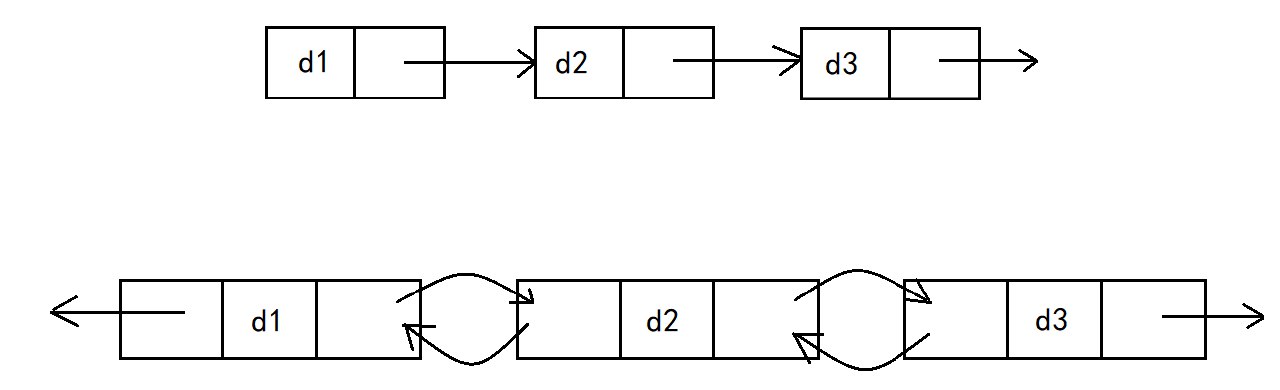
头结点(Head):链表的第一个节点。对于空链表来说,头结点为 null 或者说没有头结点。
-
尾结点(Tail):链表的最后一个节点,其链接域通常为 null,表示链表的结束。
-
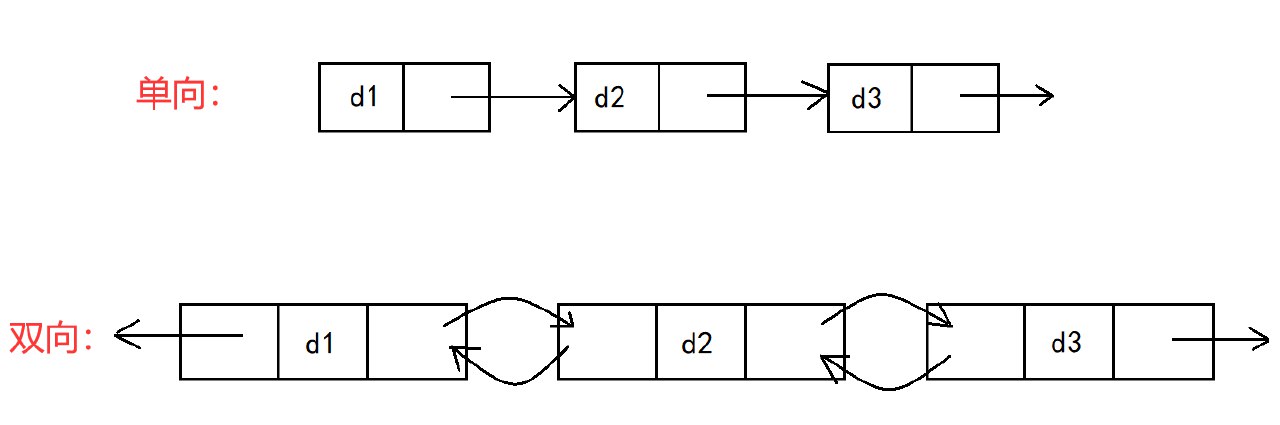
单向链表(Singly Linked List):最简单的链表类型,其中每个节点只有一个指向其后继节点的链接。
-
双向链表(Doubly Linked List):除了有一个指向前驱节点的额外链接外,其余与单向链表相同。这使得遍历可以从前向后也可以从后向前进行。
-
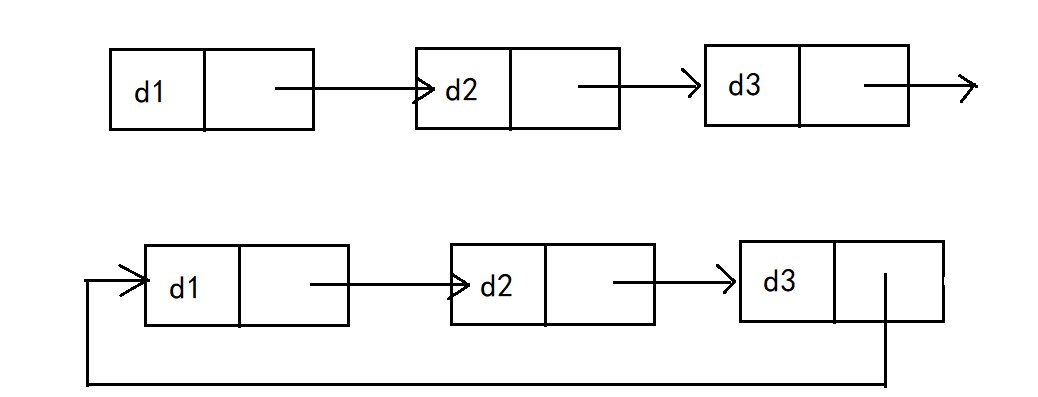
循环链表(Circular Linked List):在这种类型的链表中,最后一个节点指向的是第一个节点,而不是 null。这样就形成了一个闭环,遍历时需要特别注意以避免陷入无限循环。
链表的主要优点包括插入和删除操作简单快速,因为只需要改变相关的链接即可。但是查找某个特定元素可能需要遍历整个链表,因此效率较低。此外,链表不支持随机访问,即不能直接通过索引访问链表中的元素,只能从头节点开始逐个遍历。
在FreeRtos中就的用到了大量的链表来实现任务控制块管理,以及消息队列等都是基于链表实现的。通过使用链表,FreeRTOS能够有效地管理内部资源,并提供高效的调度和其他系统服务。链表的动态特性和灵活性非常适合实时操作系统中资源管理的需求。虽然实时操作系统不需要我们来手写,但是其最基本的数据结构,我们有必要知道其所以然。链表描述起来比较抽象,所以直接看图。
结构

图中:2.3.4.5都是结构体,称之为结点,与顺序表不同的是,链表中的每个结点不是只单纯的存一个数据。而是一个结构体,结构体成员包括一个所存的数据,和下一个结点的地址。另外,顺序表中的地址是连续的,而链表中结点的地址是随机分配的。
运行
图中的phead指针中存放的是第一个结点的地址,那么根据指着地址我们就可以找到这个结构体,又因为这个结构体中存放了下一个结构体的地址,所以又可以找到第二个结构体,循环往复就可以找到所有的结点,直到存放空地址的结构体。
特点
- 从图中可以看出,链式结构在逻辑上是连续的,但在物理上不一定连续。
- 现实中的结点一般都是从堆上申请出来的。
- 从堆上申请的空间,是按照一定的策略来分配的,两次申请的空间可能连续,也可能不连续。
链表的分类
-
单向或者双向
-
带头或不带头
-
循环或非循环
-
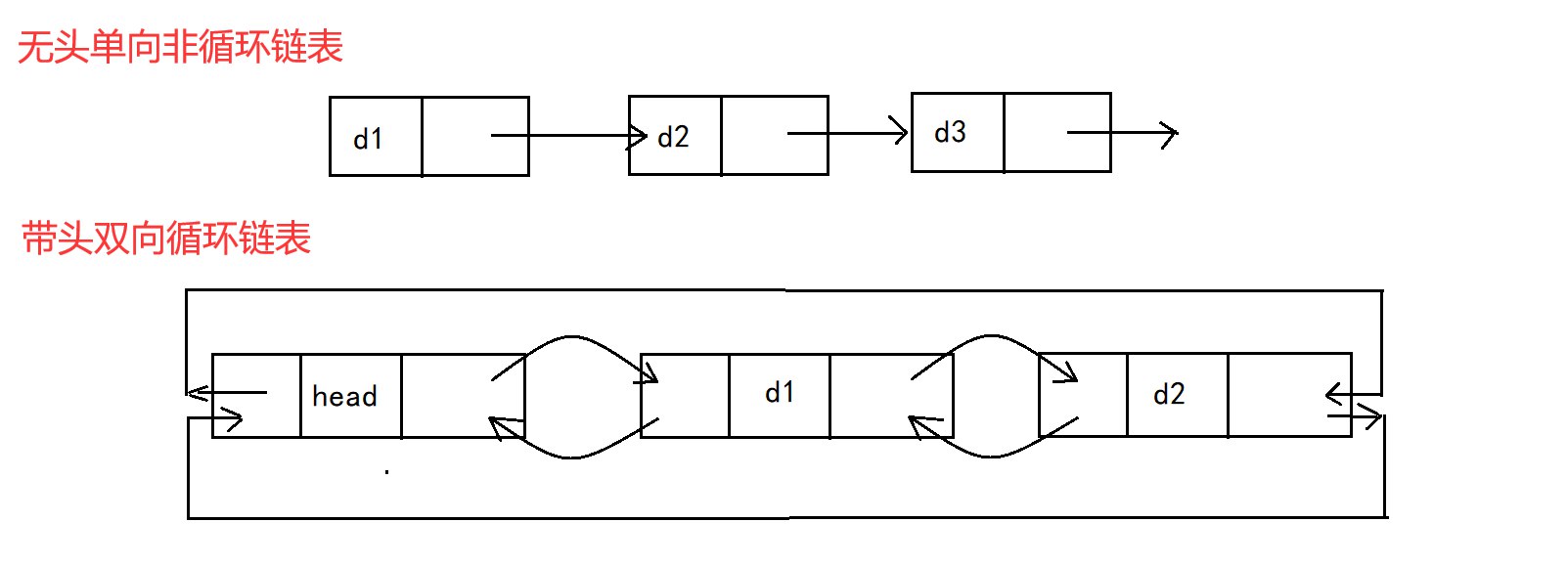
最常用的两种结构
链表的实现
无头单向非循环链表-C语言实现
目标
实现无头单向非循环链表的增、删、改、查。
- 增
节点创建、头插、尾插、指定位置前插、指定位置后插。
- 删
头删、尾删、指定位置删除。
- 改
指定节点改。
- 查
查找指定数据节点
以及节点数据的遍历输出,方便观察结果,进行对比调试。
一个无头单向非循环链表的连接如图所示。
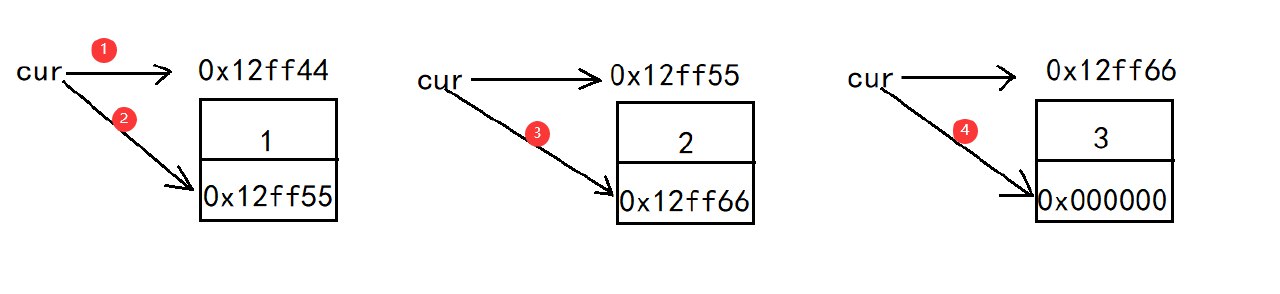
链表的数据结构
1
2
3
4
5
6
7
8
9
10
11
|
typedef uint8_t nodedata;
typedef struct node
{
nodedata data;
struct node *next;
} node;
|
链表创建
链表的每一个结点都是动态开辟(malloc)出来的,每一个结点的大小为该结构体的大小。开辟成功后,要将结点存放的数据置为需要存放的值,结点存放的地址置为NULL。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
node *lLNodeCraet(nodedata d)
{
node *newnode = (node *)malloc(sizeof(node));
if (newnode == NULL)
{
perror("malloc:error");
exit(-1);
}
newnode->data = d;
newnode->next = NULL;
return newnode;
}
|
链表头插
头插相对来说比较简单,直接将申请结点的next置为头结点,然后将头结点改成申请结点即可
注:这里不需要考虑链表是否为空,传入的指针指向空地址便是创建头节点。
1
2
3
4
5
6
7
8
9
10
11
12
|
void lLPushFront(node **pphead, nodedata d)
{
assert(pphead);
node *newnode = lLNodeCraet(d);
newnode->next = *pphead;
*pphead = newnode;
}
|
链表尾插
因为不能根据下标访问元素(即不能随机访问),当然我们也不知到最后一个结点的位置,所在尾插时,需要遍历找到最后一个结点的位置。
同时这里分为两种情况:
- 如果链表为空,则直接插入即可。
- 如果链表不为空,则需要找到尾结点再插入。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
void lLPushBack(node **pphead, nodedata d)
{
assert(pphead);
node *newnode = lLNodeCraet(d);
if (*pphead == NULL)
{
*pphead = newnode;
}
else
{
node *cur = *pphead;
while (cur->next)
{
cur = cur->next;
}
cur->next = newnode;
}
}
|
链表指定位置后插
这里在指定位置后面插入而不在前面插入是因为,在前面插入时需要找到插入位置前面的地址,而这样又会遍历一次链表,时间复杂度为O(N),而在后面插入则直接插入即可,时间复杂度为O(1)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
void lLInsertPB(node** pphead, node* pos, nodedata d)
{
assert(pphead && pos);
node* newnode = lLNodeCraet(d);
node* next = pos->next;
pos->next = newnode;
newnode->next = next;
}
|
链表指定位置前插
指定位置前插需要对链表进行遍历,细分为两种情况:
- 指定位置为头节点
- 指定位置非头节点
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
void lLInsertPF(node** pphead, node* pos, nodedata d)
{
assert(pphead);
assert(pos);
node* newnode = lLNodeCraet(d);
if (*pphead == pos)
{
newnode->next = *pphead;
*pphead = newnode;
}
else
{
node* posPrev = *pphead;
while (posPrev->next != pos)
{
posPrev = posPrev->next;
}
posPrev->next = newnode;
newnode->next = pos;
}
}
|
链表尾删
同尾插一样,我们也不知道尾结点的地址,所以需要先找到尾结点。同时这里需要考虑三种情况:
- 链表为空。
- 链表中只有一个结点。
- 链表中有一个以上结点。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
nodedata lLPopBack(node **pphead)
{
assert(*pphead && pphead);
nodedata t;
if ((*pphead)->next == NULL)
{
t = (*pphead)->data;
free(*pphead);
*pphead = NULL;
return t;
}
node *cur = *pphead;
node *next = (*pphead)->next;
while (next->next)
{
next = next->next;
cur = cur->next;
}
t = next->data;
cur->next = NULL;
free(next);
next = NULL;
return t;
}
|
链表头删
头删也比较简单,相当于将头指针移动到第二个结点上。这里分为两种情况:
- 链表为空。
- 链表不为空。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
nodedata lLPopFront(node **pphead)
{
assert(*pphead && pphead);
nodedata t;
t = (*pphead)->data;
node *next = (*pphead)->next;
free(*pphead);
*pphead = next;
return t;
}
|
链表指定位置删除
这里在指定位置删除,而不在前面删除或者后面删除,是因为在头删和尾删时会遇到一些麻烦。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
nodedata lLErase(node **pphead, node *pos)
{
assert(pphead && pos);
nodedata t;
if (*pphead == pos)
{
t = (*pphead)->data;
*pphead = (*pphead)->next;
free(pos);
pos = NULL;
return t;
}
else
{
node *cur = *pphead;
while (cur->next != pos)
{
cur = cur->next;
}
t = cur->data;
cur->next = pos->next;
free(pos);
pos = NULL;
return t;
}
}
|
链表通过数据查找节点
根据提供的数据,在链表中遍历每个结点,若某个结点中的数据与之相同则返回该结点的地址;若没有找到则返回NULL。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
node* lLFind(node* phead, nodedata d)
{
while (phead)
{
if (phead->data == d)
{
return phead;
}
phead = phead->next;
}
return NULL;
}
|
链表销毁
保存下一个结点的地址,释放当前结点,再将指针指向下一个结点,释放下一个结点,直到链表为空。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
void lLDestory(node** pphead)
{
assert(pphead);
while (*pphead)
{
node* next = (*pphead)->next;
free(*pphead);
*pphead = next;
}
}
|
链表遍历打印
保存下一个结点的地址,打印当前结点数据,再将指针指向下一个结点,直到链表为空,输出NULL。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
void lLPrint(node* phead)
{
node* cur = phead;
while (cur)
{
printf("%d->", cur->data);
cur = cur->next;
}
printf("NULL\n");
}
|
链表测试
测试所有的函数 观测输出结果是否和预期一致
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| int main(void)
{
node *Head = NULL;
lLPushFront(&Head, 0);
lLPushFront(&Head, 1);
lLPushFront(&Head, 2);
lLPushFront(&Head, 3);
lLPushFront(&Head, 4);
lLPushFront(&Head, 5);
lLPushBack(&Head, 99);
lLPushFront(&Head, 66);
node *index1 = lLFind(Head, 4);
lLInsertPB(&Head, index1, 12);
lLInsertPF(&Head, index1, 13);
node *index2 = lLFind(Head, 2);
lLPushBack(&Head, 91);
lLPushFront(&Head, 61);
lLPushBack(&Head, 92);
lLPushFront(&Head, 62);
lLPopBack(&Head);
lLPopFront(&Head);
lLErase(&Head, index2);
lLPrint(Head);
return 0;
}
|
从输出结果观测到 输出结果和预期表现一致,表面链表实现没有问题

源码获取
github https://github.com/freedom413/linklistDemo.git






